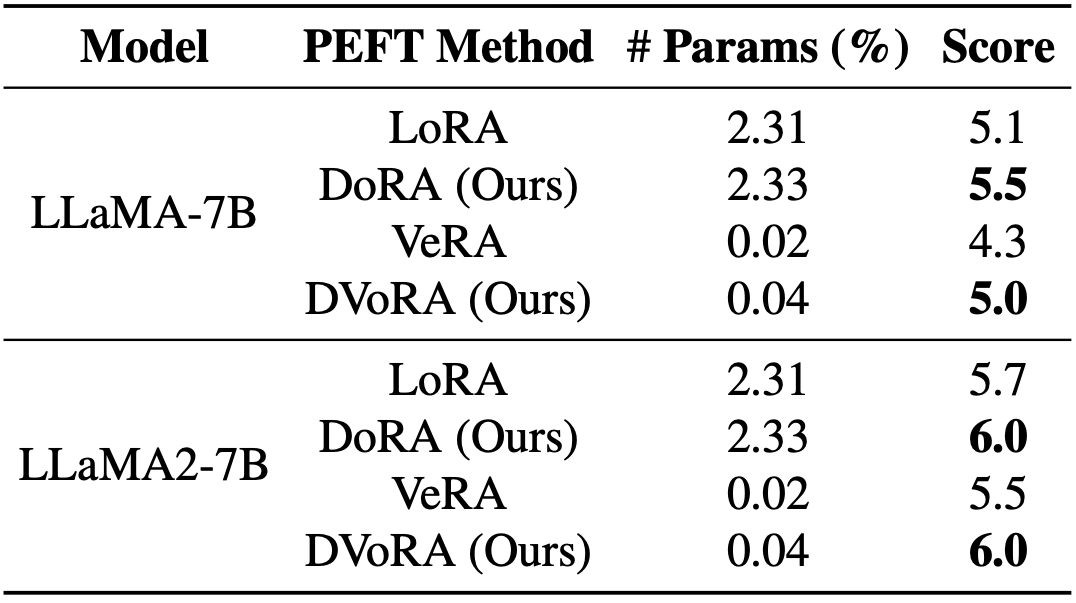
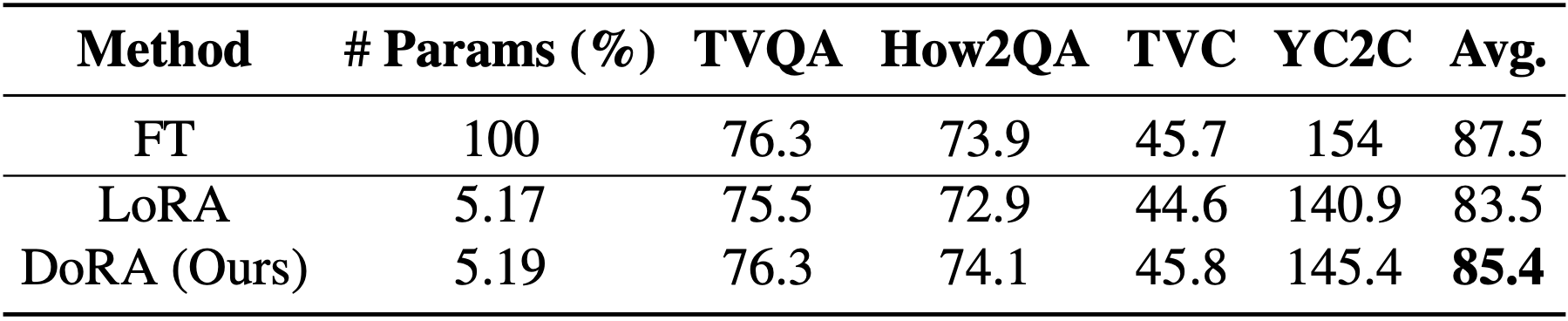
Among the widely used parameter-efficient finetuning (PEFT) methods, LoRA and its variants have gained considerable popularity because of avoiding additional inference costs. However, there still often exists an accuracy gap between these methods and full fine-tuning (FT). In this work, we first introduce a novel weight decomposition analysis to investigate the inherent differences between FT and LoRA. Aiming to resemble the learning capacity of FT from the findings, we propose Weight-Decomposed LowRank Adaptation (DoRA). DoRA decomposes the pre-trained weight into two components, magnitude and direction, for fine-tuning, specifically employing LoRA for directional updates to efficiently minimize the number of trainable parameters. By employing DoRA, we enhance both the learning capacity and training stability of LoRA while avoiding any additional inference overhead. DoRA consistently outperforms LoRA on fine-tuning LLaMA, LLaVA, and VL-BART on various downstream tasks, such as commonsense reasoning, visual instruction tuning, and image/video-text understanding.
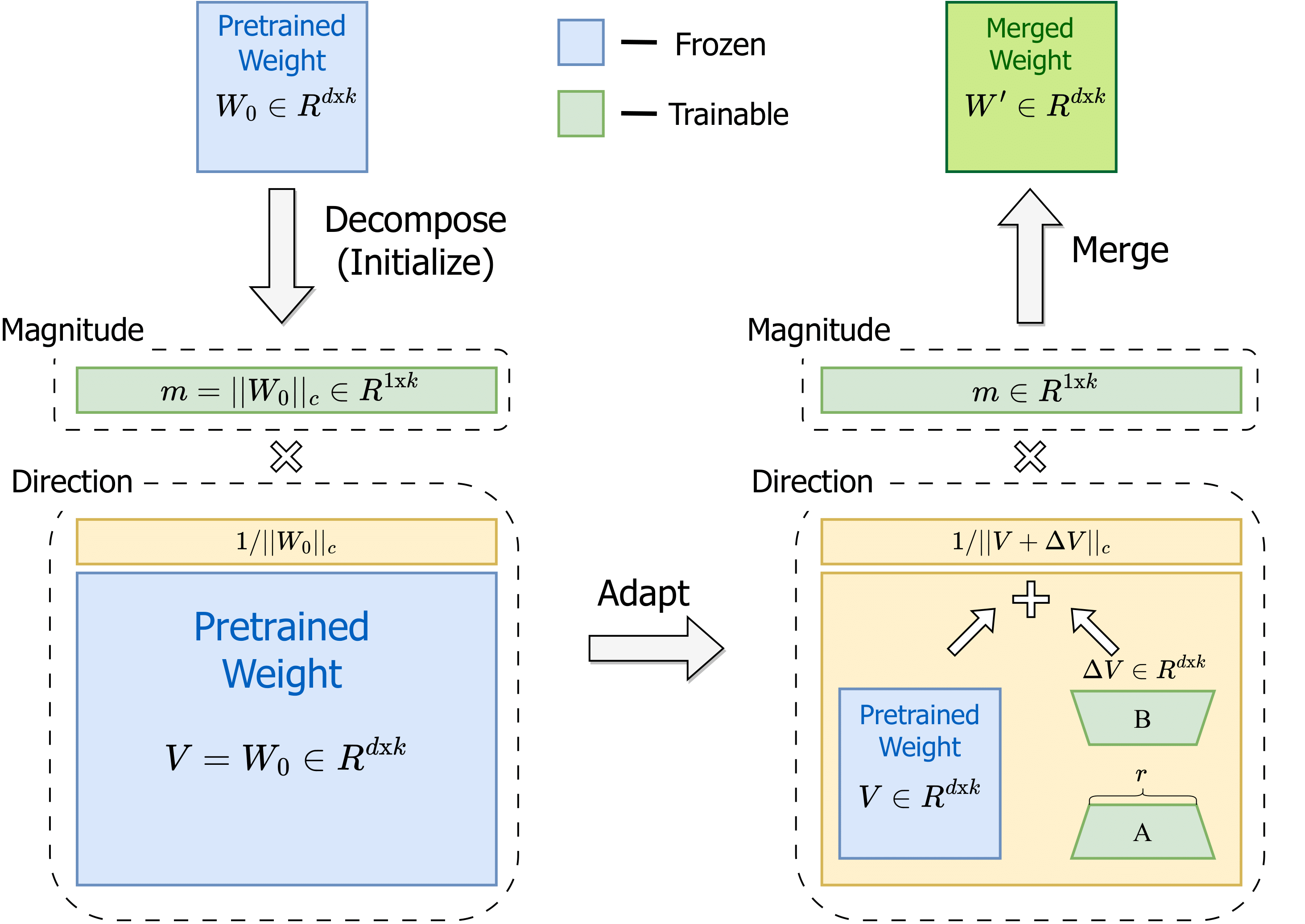
An overview of our proposed DoRA, which decomposes the pre-trained weight into magnitude and direction components for fine-tuning, especially with LoRA to efficiently update the direction component.



## LoRA forward pass
def forward(self, x: torch.Tensor):
base_result = F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias)
dropout_x = self.lora_dropout(x)
result += (self.lora_B(self.lora_A(dropout_x.to(self.lora_A.weight.dtype)))) * self.scaling
return result
## DoRA forward pass
def forward(self, x: torch.Tensor):
base_result = F.linear(x, transpose(self.weight, self.fan_in_fan_out))
dropout_x = self.lora_dropout(x)
new_weight_v = self.weight + (self.lora_B.weight @ self.lora_A.weight) * self.scaling
norm_scale = self.weight_m_wdecomp.weight.view(-1) / (torch.linalg.norm(new_weight_v,dim=1)).detach()
result = base_result + (norm_scale-1) * (F.linear(dropout_x, transpose(self.weight, self.fan_in_fan_out)))
result += ( norm_scale * (self.lora_B(self.lora_A(dropout_x.to(self.lora_A.weight.dtype))))) * self.scaling
if not self.bias is None:
result += self.bias.view(1, -1).expand_as(result)
return result
git clone https://github.com/AnswerDotAI/fsdp_qlorapip install git+https://github.com/huggingface/peft.git -q
from peft import LoraConfig, get_peft_model
# Initialize DoRA configuration
config = LoraConfig(
...
use_dora=True
...
)


@article{liu2024dora,
title={DoRA: Weight-Decomposed Low-Rank Adaptation},
author={Liu, Shih-Yang and Wang, Chien-Yi and Yin, Hongxu and Molchanov, Pavlo and Wang, Yu-Chiang Frank and Cheng, Kwang-Ting and Chen, Min-Hung},
journal={arXiv preprint arXiv:2402.09353},
year={2024}
}